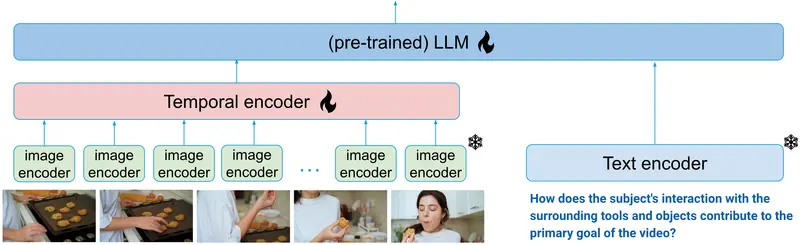
Salesforce AI研究所推出一种用于视频的多模态语言模型xGen-MM-Vid(BLIP-3-Video),特别设计用于高效捕捉多帧之间的时间信息。BLIP-3-Video除了传统的视觉标记器外,还利用了“时间编码器”,该编码器将多帧上的标记序列映射为一组紧凑的视觉标记。这使得BLIP-3-Video能够使用比其竞争模型(例如,32 vs. 4608个标记)少得多的视觉标记。
研究人员探索了不同类型的时间编码器,包括可学习的时空池化以及像Token Turing Machines这样的序列模型。通过实验证实,BLIP-3-Video在视频问答准确性方面与更大的最先进模型(例如,34B)相当,同时更小(即,4B)且更高效,使用更少的视觉标记。
想象一下,你有一台超级电脑,它不仅能看懂视频里的内容,还能回答你关于视频的问题。这篇论文就是关于这样一个聪明的电脑程序,它的名字叫“BLIP-3-Video”。这个程序特别擅长从视频中提取关键信息,并且用非常少的“标签”(我们称之为“视觉令牌”)来代表整个视频。
主要功能和特点
- 少即是多:BLIP-3-Video能够用仅仅32个视觉令牌来代表一个视频,而其他同类模型可能需要几千个。
- 高效捕捉时间信息:它通过一个特殊的“时间编码器”来理解视频中随时间变化的内容。
- 小而强大:尽管模型较小(只有4B参数),但性能却可以与更大的模型(比如34B参数)相媲美。
工作原理
BLIP-3-Video的工作原理可以分为以下几个步骤:
- 视觉编码:首先,它使用一个预训练的图像编码器(比如ViT)来处理视频的每一帧图像。
- 帧级标记化:然后,它通过一个标记器将图像转换成一定数量的视觉令牌。
- 时间编码:接下来,时间编码器登场,它将一系列帧级视觉令牌抽象成更少的视频级视觉令牌。
- 文本输出:最后,一个自回归的语言模型(LLM)根据这些视频令牌和文本提示生成输出文本。
具体应用场景
BLIP-3-Video可以应用在很多需要理解和回答视频内容的场景中,比如:
- 视频问答:比如你可以问电脑,“这个视频是关于什么的?”电脑能够理解视频内容并给出答案。
- 视频描述生成:电脑可以自动为视频生成描述性的文本,帮助人们快速了解视频内容。
- 视频内容分析:在安全监控等领域,BLIP-3-Video可以帮助自动识别和分析视频中的重要事件。
总的来说,BLIP-3-Video就是一个让电脑更聪明地处理视频信息的工具,让电脑在理解视频方面变得更加高效和准确。