知识蒸馏(Knowledge Distillation,简称KD)是一种常用的技术,用于训练小型、高性能的学生语言模型(LMs),利用大型教师LMs的知识。尽管KD在微调中表现出色,但在预训练过程中面临效率、灵活性和有效性的挑战。现有方法要么因为在线教师推理导致高计算成本,要么需要教师和学生LMs之间的标记匹配,或者冒着丢失教师生成的训练数据的难度和多样性的风险。
MINIPLM:解决问题的新框架
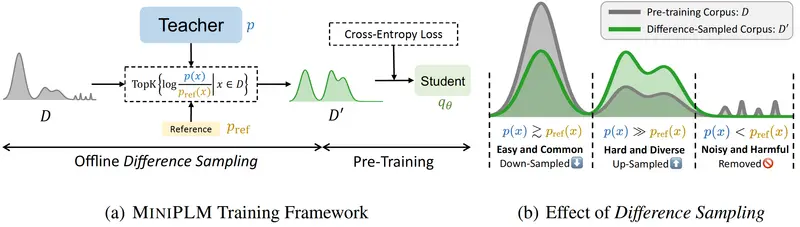
为了解决这些问题,清华大学CoAI团队和微信AI的研究人员提出了MINIPLM,这是一个通过用教师的知识细化训练数据分布来预训练LMs的KD框架。
- GitHub:https://github.com/thu-coai/MiniPLM
- 模型:https://huggingface.co/collections/MiniLLM/miniplm-6712c0fdf09ef7e8da7d39bd
主要特点
效率
- 离线教师推理:MINIPLM通过离线方式进行教师LM推理,允许对多个学生LMs进行KD,而不会增加训练时间成本。
灵活性
- 操作训练语料库:MINIPLM仅在训练语料库上操作,不需要教师和学生LMs之间的标记匹配,因此可以在不同的模型家族之间进行KD。
效果
- 增强训练数据:MINIPLM利用大型和小型LMs之间的差异来增强训练数据的难度和多样性,帮助学生LMs获得更广泛和复杂的知识。
工作原理
MINIPLM的工作原理基于“差异采样”(Difference Sampling),具体步骤如下:
- 减少简单和常见模式的样本:这些是大型和小型模型都能轻松处理的,因此它们的价值不大。
- 增加困难和多样化实例的样本:这些是大型模型能处理,但小型模型处理起来有难度的,对小型模型的学习更有帮助。
- 过滤掉噪声或有害数据点:这些是大型模型认为不重要的数据,小型模型也不应该在上面浪费时间。
实验结果
大量的实验证明,MINIPLM提高了学生LMs在9个广泛使用的下游任务上的性能,改善了语言建模能力,并减少了预训练计算。MINIPLM的好处延伸到了大规模预训练,这一点从规模曲线的外推得到了证明。进一步的分析揭示,MINIPLM支持跨模型家族的KD,并提高了预训练数据的使用率。
具体应用场景
预训练小型语言模型
- 资源有限:在资源有限的情况下,使用MINIPLM可以训练出性能接近大型模型的小型模型,用于各种NLP任务,如文本分类、情感分析、问答系统等。
跨模型家族的知识蒸馏
- 不同架构:不同的NLP模型可能有不同的架构和标记化方法,MINIPLM可以帮助这些模型之间传递知识。
数据受限的情况
- 数据量有限:在数据量有限或者获取数据成本较高的情况下,MINIPLM可以提高数据的利用效率,减少对新数据的需求。
结论
MINIPLM作为一个高效的预训练语言模型知识蒸馏框架,通过离线教师推理、操作训练语料库和增强训练数据,解决了现有方法的效率、灵活性和有效性问题。MINIPLM不仅提高了学生LMs的性能,还在多个应用场景中展现出显著的优势。总的来说,MINIPLM像是一个桥梁,连接了大型和小型语言模型,让小型模型站在大型模型的肩膀上,看得更远,学得更多。