百川对齐(Baichuan Alignment)是对百川系列模型所采用的对齐技术进行的一次详尽剖析。作为业内首个全面解析对齐方法论的报告,它为推进人工智能研究提供了宝贵见解。本文档深入探讨了提升模型对齐过程中表现的关键要素,包括优化方法、数据策略、能力增强及评估流程等方面。
- 论文地址:https://arxiv.org/abs/2410.14940
- 模型:https://huggingface.co/PKU-Baichuan-MLSystemLab/Llama3-PBM-Nova-70B
对齐过程概述
百川对齐过程主要分为三个核心阶段:
- Prompt增强系统(PAS):通过改进提示语的设计,使模型更好地理解和回应用户的意图。此阶段重点在于提高模型的理解力和表达力。
- 监督微调(SFT):利用标注数据对模型进行精细化调整,以优化其特定任务上的性能。这是确保模型在实际应用中达到最佳效果的重要步骤。
- 偏好对齐:根据用户反馈不断调整模型,使其更符合用户的期望和偏好。此阶段强调用户体验的重要性,并致力于实现个性化服务。
技术挑战与解决方案
报告详细记录了在实施对齐技术过程中遇到的问题及其解决办法。例如,在处理大规模数据集时如何保持模型稳定性和效率,以及如何平衡模型泛化能力和特定任务上的专长等。
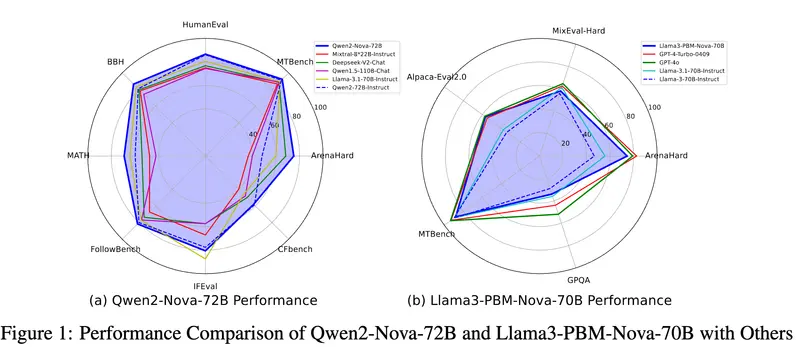
性能对比与评估
通过对多个知名基准测试的比较,本报告展示了百川对齐技术带来的技术进步。百川指令版模型(Baichuan-Instruct)在其核心能力方面实现了显著提升,用户体验改善幅度达到了17%至28%,并在专业基准测试中表现出色。
主要功能和特点:
- 提示增强系统(PAS):通过自动化的提示工程技术,将用户查询转换为模型更容易理解和执行的指令。
- 监督式微调(SFT):使用大量高质量和多样化的数据,使模型能够进行对话和处理复杂任务。
- 偏好对齐:进一步使模型与人类的价值观和偏好对齐。
工作原理:
- 训练和优化:使用特定的学习率进行监督式微调,并采用样本打包、权重衰减等技术来提高训练效率和模型性能。
- 奖励模型:基于偏好数据使用Bradley-Terry模型估计奖励函数,并添加均方误差损失以提高模型的鲁棒性。
- 强化学习:实验了PPO和GRPO方法来进一步提升模型性能,通过KL散度和策略模型之间的差异来优化模型。
- 数据策略:包括提示选择、响应构建和偏好数据的构建,以确保数据的多样性和质量。
具体应用场景:
- 对话系统:在聊天机器人或虚拟助手中,百川对齐技术可以提升对用户意图的理解和对话的自然度。
- 任务自动化:在自动化任务执行中,该技术可以帮助模型更好地遵循复杂的指令,提高任务完成的准确性和效率。
- 个性化服务:通过偏好对齐,模型能够提供更符合用户个人偏好的服务,如个性化推荐系统。
百川对齐技术的报告不仅展示了其在多个模型上的应用效果,还通过与现有技术的比较,突显了其技术进步,特别是在特定基准测试中的表现。这项技术的目标是推动人工智能向通用人工智能(AGI)的方向发展。