检索增强生成(RAG)作为一种有效补充大语言模型(LLMs)的技术手段,近年来受到了广泛关注。然而,RAG在处理知识密集型任务时,往往因为忽略了文本分块的重要性而影响最终结果的质量。为此,中国人民大学和上海先进算法研究所的研究团队提出了“元分块”(Meta-Chunking)的概念,旨在通过更精细的文本分割策略,进一步优化RAG模型的表现。这种技术特别适用于增强大语言模型(LLMs)在知识密集型任务中的表现,例如开放域问答。
例如,你有一个长篇文章,需要将其分割成几个部分以便更好地理解和检索信息。传统的方法是按照句子或段落来分割,但这种方法可能无法捕捉到句子间的深层逻辑联系。Meta-Chunking技术能够识别出那些在逻辑上紧密相连的句子集合,并将它们作为一个整体进行处理。例如,在处理一个关于历史事件的长篇文章时,Meta-Chunking能够识别出描述事件起因、过程和结果的句子集合,并将它们分别作为一个独立的块,从而在后续的信息检索或问答任务中提供更准确的上下文。

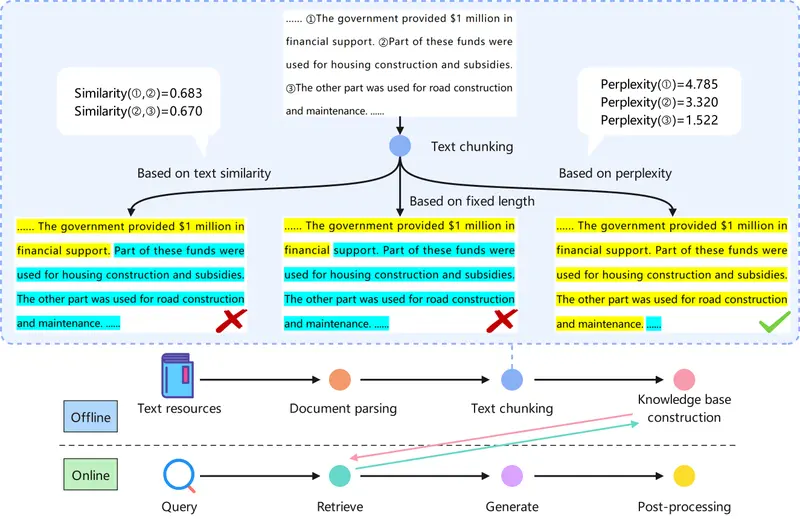
元分块的概念
元分块位于句子和段落之间,是指由段落中具有深层次语言逻辑联系的句子组成的集合。这种分块方式既保留了句子间的逻辑关系,又避免了传统段落划分可能导致的信息过载或不足问题。
主要功能和特点:
- 粒度控制:Meta-Chunking在句子和段落之间提供了一个新的粒度级别,称为元块(Meta-Chunk),它由段落内逻辑上深度相连的句子集合组成。
- 两种策略:论文提出了两种基于LLMs的策略——边际采样分割(Margin Sampling Chunking)和困惑度分割(Perplexity Chunking)——来实现Meta-Chunking。
- 动态合并:考虑到不同文本的固有复杂性,论文还提出了一种将Meta-Chunking与动态合并相结合的策略,以在细粒度和粗粒度文本分割之间取得平衡。
工作原理:
- 边际采样分割:通过LLMs对连续句子是否需要分割进行二元分类,基于边际采样得到的概率差异来做出决策。
- 困惑度分割:通过分析每个句子的困惑度(Perplexity)分布特征来精确识别文本块的边界。
- 动态合并:根据用户指定的块长度,迭代合并相邻的元块,直到总长度满足或接近要求。
实验验证
研究人员在十一个不同的数据集上进行了实验,结果显示元分块技术能够显著提高基于RAG模型的单跳和多跳问答任务的性能。特别是在2WikiMultihopQA数据集上,元分块技术相比传统的相似性分块方法,不仅准确率提升了1.32%,而且处理速度提高了约54.2%。
具体应用场景:
- 问答系统:在问答系统中,Meta-Chunking可以帮助模型更准确地理解和检索文档中的信息,从而提供更准确的答案。
- 信息检索:在信息检索任务中,通过更合理地分割文本,可以提高检索系统的效率和准确性。
- 文本摘要:在自动文本摘要中,Meta-Chunking可以帮助识别和提取关键信息,生成更连贯和信息丰富的摘要。
- 教育和研究:在学术研究和教育领域,Meta-Chunking可以辅助研究人员和学生更好地组织和理解长篇文献资料。