
Meta 发布了 Llama 3.2 1B和3B的官方量化版本,提供了更小的内存占用、更快的设备推理速度、准确性和便携性。 量化模型实现了 2-4 倍的速度提升,模型大小减少了 56%,内存使用量减少了 41%,量化技术包括 Quantization-Aware Training with LoRA 适配器和 SpinQuant,这两种方法分别优先考虑了准确性和可移植性。
- 地址:https://www.llama.com
- 模型:https://huggingface.co/collections/meta-llama/llama-32-66f448ffc8c32f949b04c8cf
要点:
- 今天,我们发布了首批轻量级量化的 Llama 模型,这些模型体积小且性能高,足以在许多流行的移动设备上运行。在 Meta,我们拥有独特的优势来提供量化模型,因为我们能够访问计算资源、训练数据、全面评估和安全性。
- 作为 Llama 系列中的首批量化模型,这些指令调优模型不仅保持了与原始 1B 和 3B 模型相同的高质量和安全性,还实现了 2-4 倍的加速。此外,相比原始的 BF16 格式,这些模型的大小平均减少了 56%,内存使用量平均减少了 41%。
- 我们采用了两种技术来量化 Llama 3.2 1B 和 3B 模型:一种是 Quantization-Aware Training with LoRA adaptors,这种方法注重准确性;另一种是 SpinQuant,这是一种最先进的后训练量化方法,注重便携性。
- 通过 PyTorch 的 ExecuTorch 框架,Llama Stack 参考实现支持使用这两种量化技术的推理。
- 我们与行业领先的合作伙伴紧密合作,确保这些量化模型能够在高通和联发科 SoC 上与 Arm CPU 兼容。
在上个月的 Connect 2024 大会上,我们开源了 Llama 3.2 1B 和 3B 模型,这是我们迄今为止最小的模型,旨在满足设备上和边缘部署的需求。自发布以来,我们不仅看到了社区对这些轻量级模型的广泛采用,还看到了开发者如何通过量化来节省容量和内存占用,尽管这可能会牺牲一些性能和准确性。
正如我们之前提到的,我们希望让更多的开发者能够轻松使用 Llama,而无需大量的计算资源和专业知识。今天,我们分享了 Llama 3.2 1B 和 3B 模型的量化版本。这些模型不仅减少了内存占用,还提供了更快的设备上推理速度、更高的准确性和更好的便携性,同时保持了开发者在资源受限设备上部署所需的质量和安全性。考虑到移动设备上有限的运行时内存,我们优先考虑了这些新量化模型的短上下文应用,最高可达 8K。我们的测试结果显示,通过量化训练,我们可以实现比后处理更高的准确性。根据使用 Android OnePlus 12 模型的测试,我们今天分享的模型实现了 2-4 倍的加速和平均 56% 的模型大小减少。我们还减少了平均 41% 的内存使用量。从今天开始,社区可以将这些量化模型部署到更多的移动 CPU 上,从而有机会构建快速且提供更多隐私的独特体验,因为所有交互都完全在设备上进行。
我们使用 Quantization-Aware Training with LoRA adaptors (QLoRA) 开发了这些最先进的模型,以优化低精度环境中的性能。我们还使用了 SpinQuant,这是一种使我们能够在保留尽可能多的质量的同时确定最佳压缩组合的技术。由于与行业领先合作伙伴的紧密合作,QLoRA 和 SpinQuant Llama 模型在 Qualcomm 和 MediaTek SoC 上与 Arm CPU 兼容。量化模型的性能已使用 Kleidi AI 内核针对移动 CPU 进行了优化,我们目前正在与合作伙伴合作,利用 NPU 为 Llama 1B/3B 实现更高的性能。
我们的量化设置
我们设计了当前的量化方案,考虑了 PyTorch 的 ExecuTorch 推理框架和 Arm CPU 后端,包括模型质量、预填充/解码速度和内存占用等指标。我们的量化方案涉及三个部分:
- 我们将所有 Transformer 块中的所有线性层量化为 4 位组内方案(组大小为 32)用于权重和 8 位每 Token 动态量化用于激活。
- 分类层被量化为 8 位每通道用于权重和 8 位每 Token 动态量化用于激活。
- 我们采用 8 位每通道量化用于嵌入。
Quantization-Aware Training 和 LoRA
我们使用 Quantization-Aware Training (QAT) 在 Llama 3.2 模型的训练过程中模拟量化的影响,使我们能够在低精度环境中优化其性能。为了初始化 QAT,我们利用了在监督微调 (SFT) 后获得的 BF16 Llama 3.2 模型检查点,并进行了额外的完整轮次的 SFT 训练与 QAT。然后我们冻结 QAT 模型的主干,并在 Transformer 块内的所有层上应用低秩适应 (LoRA) 适配器进行另一轮 SFT。同时,LoRA 适配器的权重和激活保持在 BF16。因为我们的方法在原理上类似于 QLoRA(即量化后跟 LoRA 适配器),我们在本文中称其为 QLoRA。
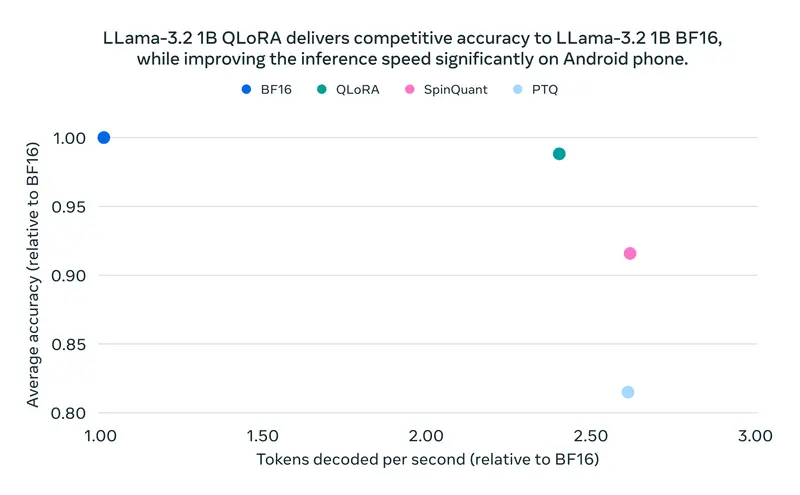
最后,我们使用直接偏好优化 (DPO) 对结果模型(主干和 LoRA 适配器)进行微调。结果模型是一个高效模型,实现了与 BF16 模型相当的准确性,同时保持了与其他量化方法相当的速度和内存占用(见下图)。
我们使用 torchao API 进行 QAT。开发者可以进一步使用 QAT 作为基础模型,并使用 LoRA 对 Llama 进行微调,以满足其定制用例,节省时间和计算成本。
SpinQuant
尽管 QAT 给出了最佳结果,但有些人可能希望量化他们微调的 1B 和 3B 模型,或者为具有不同量化设置的不同目标量化模型。为此,我们还发布了 SpinQuant 的模型和方法,这是一种最先进的后训练量化技术。
虽然该方法的准确性不如 QAT + LoRA,但 SpinQuant 的一个关键优势是其便携性,并且不需要访问训练数据集,这些数据集通常是私有的。对于数据可用性或计算资源有限的应用来说,这是一个有吸引力的解决方案。开发者可以使用这种方法,使用完全兼容 ExecuTorch 和 Llama Stack 的开源仓库,将其微调的 Llama 模型量化为不同的硬件目标和用例。
在我们的实验中,我们使用 WikiText,一个小型校准数据集,来学习 SpinQuant 中的旋转矩阵。这些矩阵使异常值平滑,并促进更有效的量化。之后,应用了诸如范围设置和生成后训练量化等量化最佳实践。SpinQuant 矩阵针对类似于 QAT + LoRA 的量化方案进行了优化。
结果
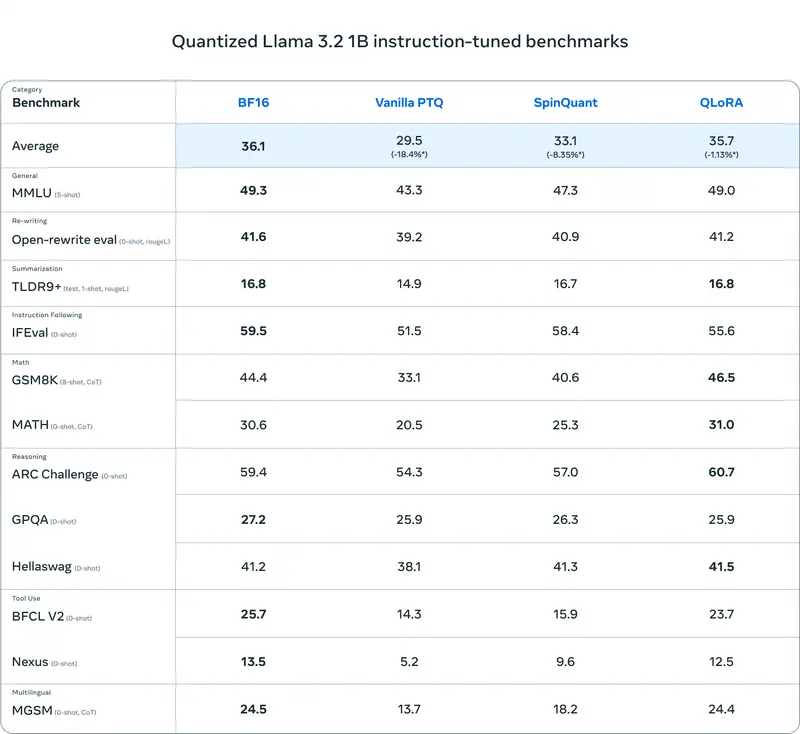
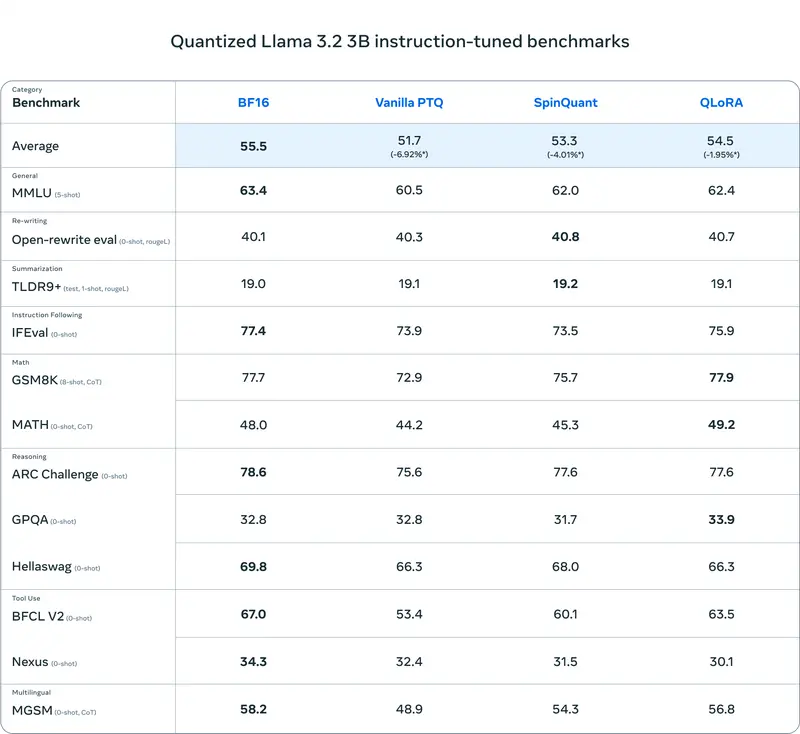
在下表中,我们展示了使用普通后训练量化 (PTQ)、SpinQuant(产生最先进的 PTQ 质量)以及 QLoRA(给出所有方法中的最佳质量)量化的模型的全面评估。
在下表中,我们比较了不同量化方法(SpinQuant 和 QAT + LoRA)与 BF16 基线的性能指标。评估使用 ExecuTorch 框架作为推理引擎,以 ARM CPU 为后端进行。量化模型主要通过利用 Kleidi AI 库针对 Arm CPU 架构进行了优化。
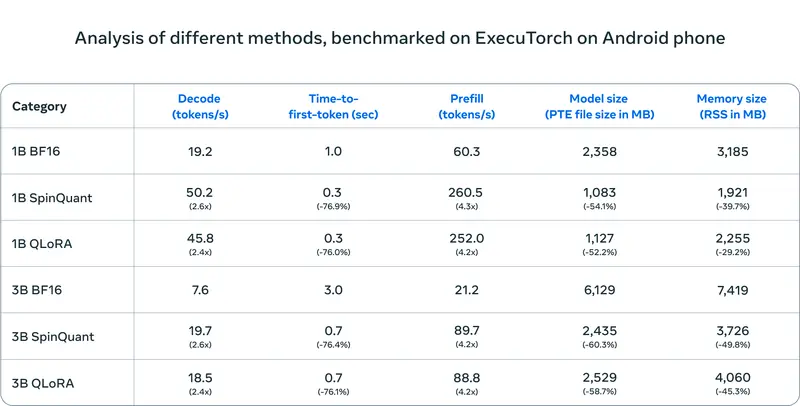
解码延迟平均提高了 2.5 倍,预填充延迟平均提高了 4.2 倍,而模型大小平均减少了 56%,内存使用量平均减少了 41%。今天可以通过 ExecuTorch Llama 指令重现这些基准。上表显示了使用 Android OnePlus 12 设备的结果——然而,我们还验证了在 Samsung S24+ 上对于 1B 和 3B 以及 Samsung S22 上对于 1B 的类似相对性能。对于 iOS 设备,我们验证了这些模型以可比的准确性运行,但尚未评估性能。
除了 CPU,我们目前正在与合作伙伴合作,利用 NPU 为这些量化模型实现更高的性能。我们的合作伙伴已经在 ExecuTorch 开源生态系统中集成了基础组件以利用 NPU,并且正在进行工作,以专门为 Llama 1B/3B 在 NPU 上启用量化。
展望未来
我们在短短时间内看到社区对 Llama 的兴奋和取得的进展感到鼓舞和鼓舞。今年,Llama 实现了 10 倍的增长,并成为负责任创新的标准。Llama 在开放性、可修改性和成本效率方面继续领先,并且在某些领域甚至领先于封闭模型。一如既往,我们迫不及待地想看到社区使用 Llama 构建的内容以及他们将在移动设备上实现的强大体验。