文章目录[隐藏]
Cohere 在 Aya 项目中发布了两个新的开源模型 Aya Expanse 8B 和 32B,旨在缩小基础模型中的语言差距,它们在 Hugging Face 上可用,在 23 种语言中扩展了性能进步。8B 参数模型便于全球研究人员获取突破,32B 参数模型具备先进的多语言能力。
- 官网:https://cohere.com
- Aya Expanse 8B:https://huggingface.co/CohereForAI/aya-expanse-8b
- Aya Expanse 32B:https://huggingface.co/CohereForAI/aya-expanse-32b
- Playground:https://dashboard.cohere.com/playground/chat
- Demo:https://huggingface.co/spaces/CohereForAI/aya_expanse
Aya Expanse 模型的特点
- 8B 参数模型:使全球研究人员更容易获得突破。
- 32B 参数模型:提供了最先进的多语言能力。
Aya 项目的背景
Aya 项目旨在将基础模型的使用范围扩大到比英语更多的全球语言。Cohere 的 AI 研究部门去年启动了 Aya 计划。今年 2 月,它发布了 Aya 101 大语言模型(LLM),这是一个覆盖 101 种语言的 130 亿参数模型。Cohere 的 AI 研究部门还发布了 Aya 数据集,以帮助扩大模型训练的其他语言的使用。

Aya Expanse 的改进
Cohere 表示,Aya Expanse 的改进是其专注于扩展 AI 如何服务于世界各地语言的结果。通过重新思考机器学习突破的核心构建块,Cohere 的研究议程包括专门致力于弥合语言差距,其中几个突破对当前配方至关重要:
- 数据套利:一种数据抽样方法,避免模型依赖合成数据时产生的胡言乱语。
- 偏好训练:用于提高一般性能和安全性。
- 模型合并:结合多个模型的优势。

Aya Expanse 的性能
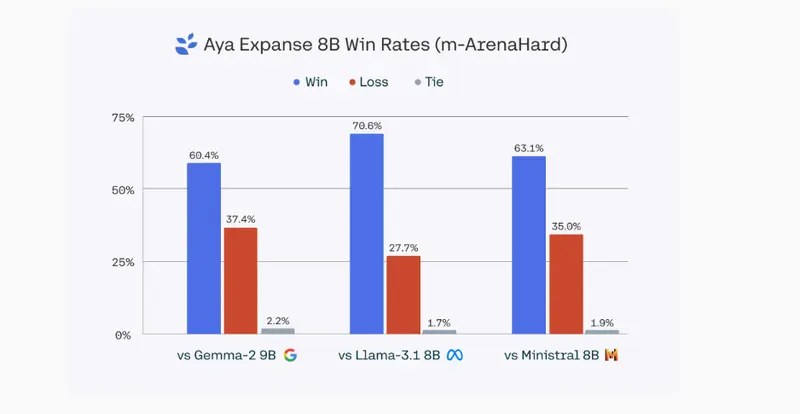
Cohere 表示,两个 Aya Expanse 模型在多语言基准测试中始终优于 Google、Mistral 和 Meta 的类似大小的 AI 模型。
- Aya Expanse 32B:在多语言基准测试中优于 Gemma 2 27B、Mistral 8x22B,甚至比更大的 Llama 3.1 70B 还要好。
- Aya Expanse 8B:优于 Gemma 2 9B、Llama 3.1 8B 和 Ministral 8B。
数据套利和偏好训练
Cohere 开发了 Aya 模型,使用了一种称为数据套利的数据抽样方法,以避免当模型依赖合成数据时产生的胡言乱语。许多模型使用由“教师”模型创建的合成数据用于训练目的。然而,由于难以找到其他语言的好的教师模型,特别是对于低资源语言。
Cohere 还专注于引导模型走向“全球偏好”,并考虑到不同的文化和语言观点。Cohere 表示,它找到了一种方法,即使在引导模型的偏好时也能提高性能和安全性。
“我们认为这是训练 AI 模型的‘最后的光芒’。然而,偏好训练和安全措施通常过度适应于在以西方为中心的数据集中普遍存在的危害。问题在于,这些安全协议通常无法扩展到多语言环境。我们的工作是首批将偏好训练扩展到大规模多语言环境的工作之一,考虑到不同的文化和语言观点。”
非英语语言的模型
Aya 计划专注于确保在非英语语言中表现良好的 LLM 的研究。许多 LLM 最终在其他语言中可用,特别是对于广泛使用的语言,但在寻找训练不同语言模型的数据时存在困难。毕竟,英语往往是政府、金融、互联网对话和商业的官方语言,因此更容易找到英语数据。
准确地对不同语言中的模型性能进行基准测试也可能很困难,因为翻译的质量问题。其他开发者已经发布了他们自己的语言数据集,以进一步研究非英语 LLM。例如,OpenAI 上个月在 Hugging Face 上发布了它的多语言大规模多任务语言理解数据集。该数据集旨在帮助更好地测试 14 种语言(包括阿拉伯语、德语、斯瓦希里语和孟加拉语)的 LLM 性能。
Cohere 的近期动态
Cohere 最近几周非常忙碌。本周,该公司在其企业嵌入产品 Embed 3 中增加了图像搜索功能,该产品用于检索增强生成(RAG)系统。这个月,它还增强了其 Command R 08-2024 模型的微调。