
文章目录[隐藏]
指令微调是一种监督微调方法,显著提高了大语言模型(LLMs)遵循人类指令的能力。对于编程任务,大多数模型通过昂贵的人工注释指令-响应对或由大型专有LLMs生成的指令-响应对进行微调,这可能不被允许。
为了克服这些限制,伊利诺伊大学厄巴纳-香槟分校、东北大学、加州大学伯克利分校、ServiceNow Research、Hugging Face、Roblox和Cursor AI的研究人员提出了SelfCodeAlign,这是一种用于代码生成的大语言模型(LLMs)的自我对齐方法。SelfCodeAlign的目标是在不需要大量人工注释或从大型专有模型中提取知识的情况下,提高模型遵循人类指令进行编程任务的能力。
GitHub:https://github.com/bigcode-project/selfcodealign
例如,我们有一个大语言模型,我们希望它能够根据自然语言指令生成代码。传统的方法是使用人工标注的数据或者依赖于其他大型模型生成的数据来微调这个模型。SelfCodeAlign提供了一种新的方法,它允许模型使用自己生成的数据进行自我对齐,从而提高其遵循指令的能力。
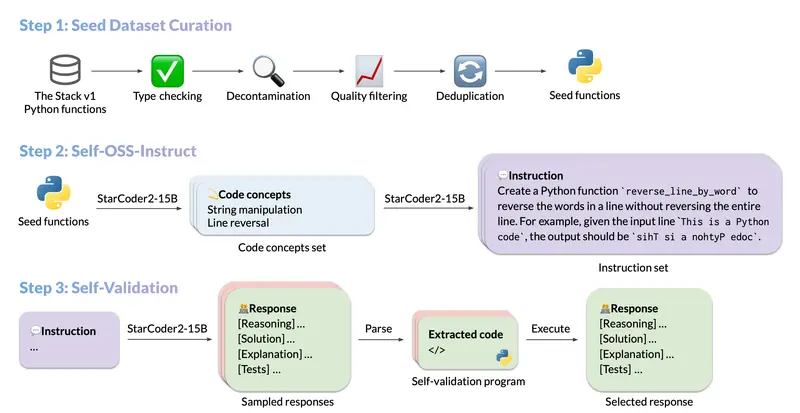
主要功能:
- 自我对齐:SelfCodeAlign能够使代码生成模型在没有人工标注数据或知识蒸馏的情况下自我改进。
- 数据生成:它通过从高质量的代码片段中提取编程概念来生成新的任务,并为每个任务生成多个响应。
- 响应验证:通过在沙盒环境中执行测试用例来验证响应的正确性。
主要特点:
- 完全透明和许可:SelfCodeAlign是第一个完全透明的、允许的代码LLM自我对齐流程。
- 跨模型有效性:它适用于不同大小的LLMs,从3B到33B。
- 性能提升:使用SelfCodeAlign微调的模型在多个基准测试中一致性地超越了原始版本。
SelfCodeAlign的工作原理
- 数据生成:
- 高质量种子代码片段:从高质量的种子代码片段中提取多样化的编程概念。
- 任务生成:使用这些编程概念生成新的编程任务。
- 响应采样:为每个任务采样多个响应。
- 测试用例配对:将每个响应与测试用例配对。
- 验证:在沙盒环境中验证每个响应。
- 选择通过的示例:通过验证的示例被选择用于指令微调。
- 微调:
- 数据集生成:使用SelfCodeAlign生成包含74,000个指令-响应对的语料库。
- 模型微调:在生成的数据集上对模型进行微调。
实验结果
- 性能提升:
- CodeQwen1.5-7B:使用SelfCodeAlign生成的数据集进行微调的CodeQwen1.5-7B模型在HumanEval+基准测试中达到了67.1的pass@1,超过了CodeLlama-70B-Instruct,尽管其大小仅为后者的十分之一。
- OctoPack对比:在所有基准测试中,微调模型始终优于使用OctoPack训练的原始版本,OctoPack是之前在没有人工注释或蒸馏的情况下进行指令微调的最先进方法。
- 模型大小的影响:
- 不同大小的LLMs:SelfCodeAlign在各种大小的LLMs(从3B到33B)中都有效。
- 基模型受益:基模型可以从与其自身数据分布的对齐中获益更多。
- 与其他方法的对比:
- GPT-4和GPT-3.5:SelfCodeAlign优于从GPT-4直接蒸馏和基于GPT-3.5的领先蒸馏方法,如OSS-Instruct和Evol-Instruct。
StarCoder2-Instruct
SelfCodeAlign还导致了StarCoder2-Instruct的创建,这是第一个完全透明、许可且自我对齐的代码LLM,实现了最先进的编码性能。
SelfCodeAlign展示了强大的指令微调代码LLM可以通过自我对齐而不是蒸馏来实现。这一方法不仅减少了对昂贵的人工注释的需求,还提供了完全透明和许可的数据生成过程。通过生成高质量的指令-响应对,SelfCodeAlign显著提高了代码LLMs的性能,使其在各种编程任务中表现出色。这一创新为代码LLM的开发和应用开辟了新的可能性,特别是在资源受限和数据隐私要求严格的场景中。