文章目录[隐藏]
Transformers已经在AI领域引发了革命,特别是在自然语言处理(NLP)、计算机视觉和多模态数据集成方面展现了卓越的性能。这些模型凭借其强大的注意力机制,能够在数据中识别复杂的模式,非常适合处理复杂的任务。然而,随着模型规模的扩大,计算成本急剧上升,成为进一步发展的瓶颈。
扩展挑战
传统的Transformers模型面临的主要挑战在于其线性投影层中的固定参数。这种静态结构限制了模型在不完全重新训练的情况下进行扩展的能力。随着模型规模的增加,这种扩展变得越来越昂贵。此外,当进行架构修改时,如增加通道维度,传统模型通常需要全面重新训练,这不仅增加了计算成本,还降低了灵活性。
历史解决方案
历史上,研究人员尝试过多种方法来管理模型的可扩展性,例如复制权重或使用 Net2Net 等技术重构模型。这些方法虽然取得了一些进展,但仍然存在局限性,尤其是在保持模型完整性和提高扩展效率方面。
Tokenformer 架构
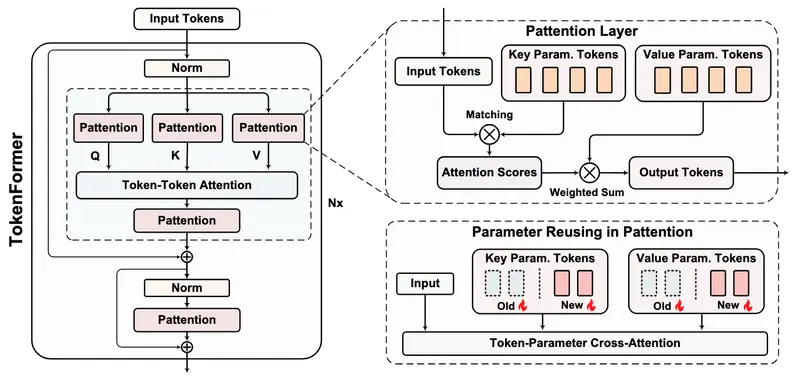
为了克服这些挑战,马克斯·普朗克研究所、谷歌和北京大学的研究人员共同开发了一种新的架构——Tokenformer。该模型重新定义了Transformers的核心概念,将模型参数视为令牌,允许令牌和参数之间的动态交互。
- 项目主页:https://haiyang-w.github.io/tokenformer.github.io
- GitHub:https://github.com/Haiyang-W/TokenFormer
- 模型:https://huggingface.co/Haiyang-W
关键技术:
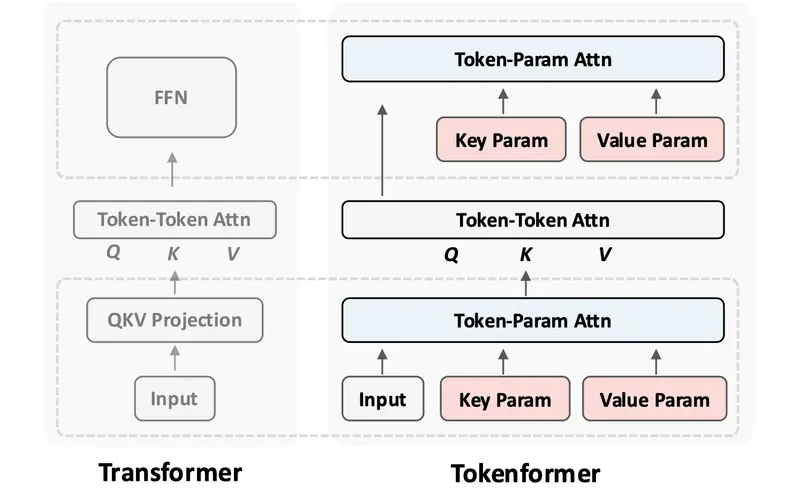
- 令牌-参数注意力(Pattention)层:这是 Tokenformer 的核心创新。Pattention 层使用输入令牌作为查询,模型参数作为键和值,从而促进增量扩展。通过这种方式,模型可以在不重新训练的情况下添加新的参数令牌,大大降低了训练成本。
- 模块化设计:Tokenformer 的架构设计为模块化,允许研究人员通过添加新的令牌无缝扩展模型。这种设计不仅支持高效重用预训练权重,还能快速适应新数据集或更大的模型规模。
性能优势
Tokenformer 在保持高准确性的同时,显著降低了计算成本。具体表现在以下几个方面:
- 显著的成本节约:与标准Transformers相比,Tokenformer 的训练成本降低了50%以上。例如,从1.24亿参数扩展到14亿参数,Tokenformer 只需传统Transformers一半的训练成本。
- 高效的增量扩展:通过添加新的参数令牌,Tokenformer 支持灵活的增量扩展,无需修改核心架构,减少了重新训练的需求。
- 保留学习到的信息:Tokenformer 保留了较小预训练模型的知识,加速了收敛,并在扩展过程中防止了学习到的信息的丢失。
- 多样化的任务表现:在基准测试中,Tokenformer 在语言和视觉建模任务中实现了具有竞争力的准确性水平,展示了其作为多功能基础模型的能力。
- 优化的令牌交互成本:通过将令牌-令牌交互成本与扩展解耦,Tokenformer 更高效地管理更长序列和更大模型。
结论
Tokenformer 为扩展基于Transformers的模型提供了一种革命性的方法。通过将参数视为令牌,Tokenformer 实现了更高的可扩展性和资源效率,降低了成本,并在各种任务中保持了模型性能。这种灵活性标志着Transformers设计的重大突破,提供了一个可以适应不断发展的 AI 应用需求而无需重新训练的模型。Tokenformer 的架构为未来的 AI 研究带来了希望,提供了一条可持续且高效地开发大规模模型的路径。