文章目录[隐藏]
在信息检索领域,创建一个能够无缝理解和检索不同格式(如文本和图像)相关内容的系统是一项极具挑战性的任务。大多数现有的检索模型仍然局限于单一模态,这限制了它们在现实世界中的应用。为了应对这一挑战,英伟达研究人员推出了 MM-Embed,这是首个在多模态 M-BEIR 基准上达到最先进(SOTA)结果的多模态检索器,并在纯文本 MTEB 检索基准上排名前五。
多模态检索的重要性
多模态检索系统能够处理文本、图像及其组合,这对于复杂应用至关重要,例如视觉问答和时尚图像检索。这些应用通常需要结合文本和图像信息来推导出相关答案。然而,跨模态理解和克服单个模态内的偏见是关键挑战。MM-Embed 的出现填补了这一空白,提供了一个更通用和有效的解决方案。

MM-Embed 的技术创新
- 双编码器架构:MM-Embed 使用双编码器架构,其中一个编码器处理文本,另一个处理图像。这种设计允许模型在处理混合模态数据时保持高效和准确。
- 模态感知硬负样本挖掘:通过引入模态感知硬负样本挖掘,MM-Embed 能够更准确地聚焦于目标模态,无论是文本、图像还是其组合。这种方法有助于减少模型中的偏见,提高检索质量。
- 持续微调:MM-Embed 经过持续微调,以提升其文本检索能力,而不会牺牲其在多模态任务中的表现。这种平衡使得模型在多种场景中都能表现出色。
- 多模态大语言模型(MLLM):MM-Embed 使用多模态大型语言模型(MLLM)作为基础,这些模型已经在大规模数据上进行了预训练,具备强大的跨模态理解能力。
实验结果与性能
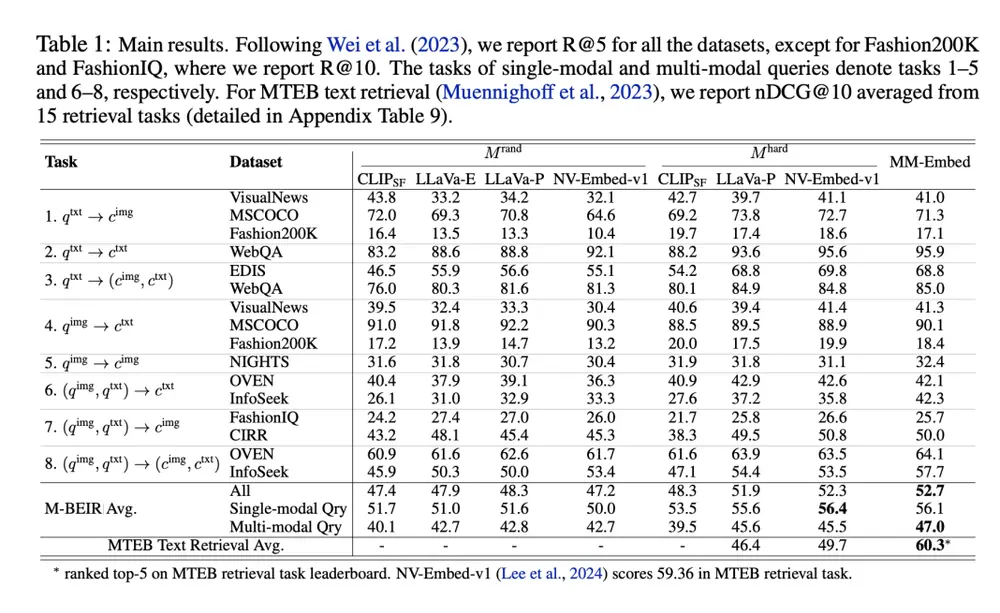
- M-BEIR 基准:MM-Embed 在 M-BEIR 基准上的平均检索准确率达到 52.7%,显著超过了之前的最先进模型。
- MSCOCO 数据集:在 MSCOCO 数据集上,MM-Embed 的检索准确率(R@5)达到 73.8%,展示了其强大的复杂图像标题理解能力。
- 视觉问答和组合图像检索:通过使用多模态 LLMs 进行零样本重排序,MM-Embed 在视觉问答和组合图像检索任务中进一步提高了检索精度。例如,在 CIRCO 的组合图像检索任务中,MM-Embed 提高了超过 7 点的排名准确性。
实际应用与意义
- 搜索引擎:MM-Embed 为构建更通用和复杂的搜索引擎铺平了道路,这些引擎能够处理多种信息格式,提供更丰富和准确的搜索结果。
- 复杂应用场景:在视觉问答、时尚图像检索等领域,MM-Embed 的多模态能力使得处理复杂查询变得更加容易,提升了用户体验。
- 学术和工业界:MM-Embed 的技术创新为学术研究和工业应用提供了新的工具和方法,推动了多模态信息检索领域的发展。
结论
MM-Embed 代表了多模态检索领域的一大飞跃。通过有效整合和增强文本和图像检索能力,它为处理当今数字环境中多样化的信息需求提供了强大的解决方案。英伟达的这一创新不仅在技术上取得了显著突破,也为未来的多模态信息检索系统奠定了坚实的基础。