文章目录[隐藏]
近年来,自动语音识别(ASR)技术取得了显著进展,正在改变从医疗保健到客户支持等多个行业。然而,在不同的语言、口音和嘈杂环境中实现准确的转录仍然是一个挑战。当前的语音转文本模型经常面临理解复杂口音、处理特定领域术语和应对背景噪音等问题。随着日常生活中AI驱动应用的普及,对更强大、适应性更强和可扩展的语音转文本解决方案的需求日益增长。
Assembly AI 的 Universal-2
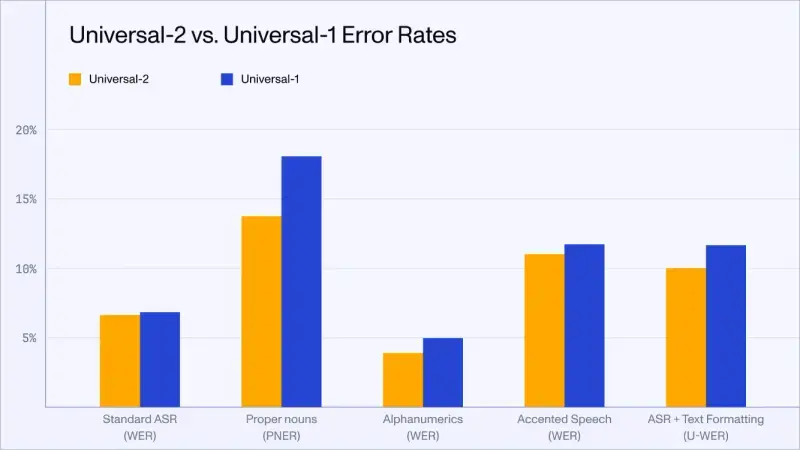
为了应对这些挑战,Assembly AI 推出了 Universal-2,这是一种新的语音转文本模型,旨在比其前身 Universal-1 提供显著的改进。这个升级模型旨在提高更广泛的语言、口音和场景中的转录准确性。Universal-2 利用了深度学习和语音处理领域的最新进展,即使在音频质量差或背景噪音大的挑战性条件下,也能更细致地理解人类语音。根据 Assembly AI 的说法,Universal-2 的发布是他们朝着创建行业中最全面和准确的 ASR 解决方案迈出的重要一步。
官方说明:https://www.assemblyai.com/research/universal-2
技术细节和优势
1. 架构和训练方法的改进
- 递归神经网络转录器(RNN-T):Universal-2 基于 RNN-T 架构,这是一种高效的 ASR 解码器,能够处理连续的语音流。
- 更广泛的数据集:该模型采用了更广泛的训练数据集,涵盖了不同的语音模式、多种方言和不同的音频质量。这有助于模型学习更具适应性和精确性,减少了与前身相比的词错误率(WER)。
2. 增强的多语言支持
- 多语言适应性:Universal-2 引入了增强的多语言支持,使其成为一个真正多功能的 ASR 解决方案,能够在各种语言和方言中提供高质量的结果。
- 低资源环境下的性能:即使在低资源环境下,Universal-2 也能保持一致的性能,这意味着在不太理想的条件下进行转录时,模型不会失效。这使其非常适合呼叫中心、播客和多语言会议等应用。
3. 噪音鲁棒性
- 噪音处理:Universal-2 的噪音鲁棒性得到了显著改进,能够更有效地处理现实世界的音频场景,如背景噪音和混响。
- 实时转录:该模型针对更快的处理速度进行了优化,能够实现接近实时的转录,这对于客户服务、直播广播和自动会议转录等领域至关重要。
性能指标和重要性
1. 词错误率(WER)
- 显著降低:Assembly AI 报告称,Universal-2 的词错误率显著降低,比 Universal-1 减少了 32%。这一改进转化为更少的转录错误、更好的客户体验和更高的效率。
2. 多语言和口音支持
- 广泛适用性:Universal-2 在不同语言和口音中的增强性能使其在语言多样性对传统 ASR 系统构成挑战的地区非常有价值。这为企业和服务开辟了新的机会,特别是在处理非英语语言或强烈地区口音时。
通过 Universal-2,Assembly AI 正在为语音转文本领域设定新的标准。该模型增强的准确性、速度和适应性使其成为希望利用最新 ASR 技术的开发者和企业的强大选择。
通过解决之前的挑战,如需要更好的噪音处理和多语言支持,Universal-2 不仅在其前身的基础上构建了优势,还引入了新的能力,使语音识别对更广泛的应用更加可访问和有效。随着各行业继续将 AI 驱动的工具整合到其工作流程中,像 Universal-2 这样的进步使我们更接近无缝的人机通信,为更直观和高效的交互奠定了基础。