文章目录[隐藏]
随着大语言模型(LLMs)的发展,从简单的链式思维提示到像OpenAI的o1这样的成熟产品,这些模型在推理能力方面已经取得了显著的进步。然而,在涉及视觉和语言的任务中,如何有效地利用高质量的长链推理数据和优化训练管道仍然是一个亟待解决的问题。
- GitHub:https://github.com/dongyh20/Insight-V
- 模型:https://huggingface.co/collections/THUdyh/insight-v-673f5e1dd8ab5f2d8d332035
InsightV的提出
近日,来自南洋理工大学S-Lab、腾讯、清华大学和南京大学的研究者们共同提出了一种新的方法——InsightV,旨在两个关键方向上做出贡献:
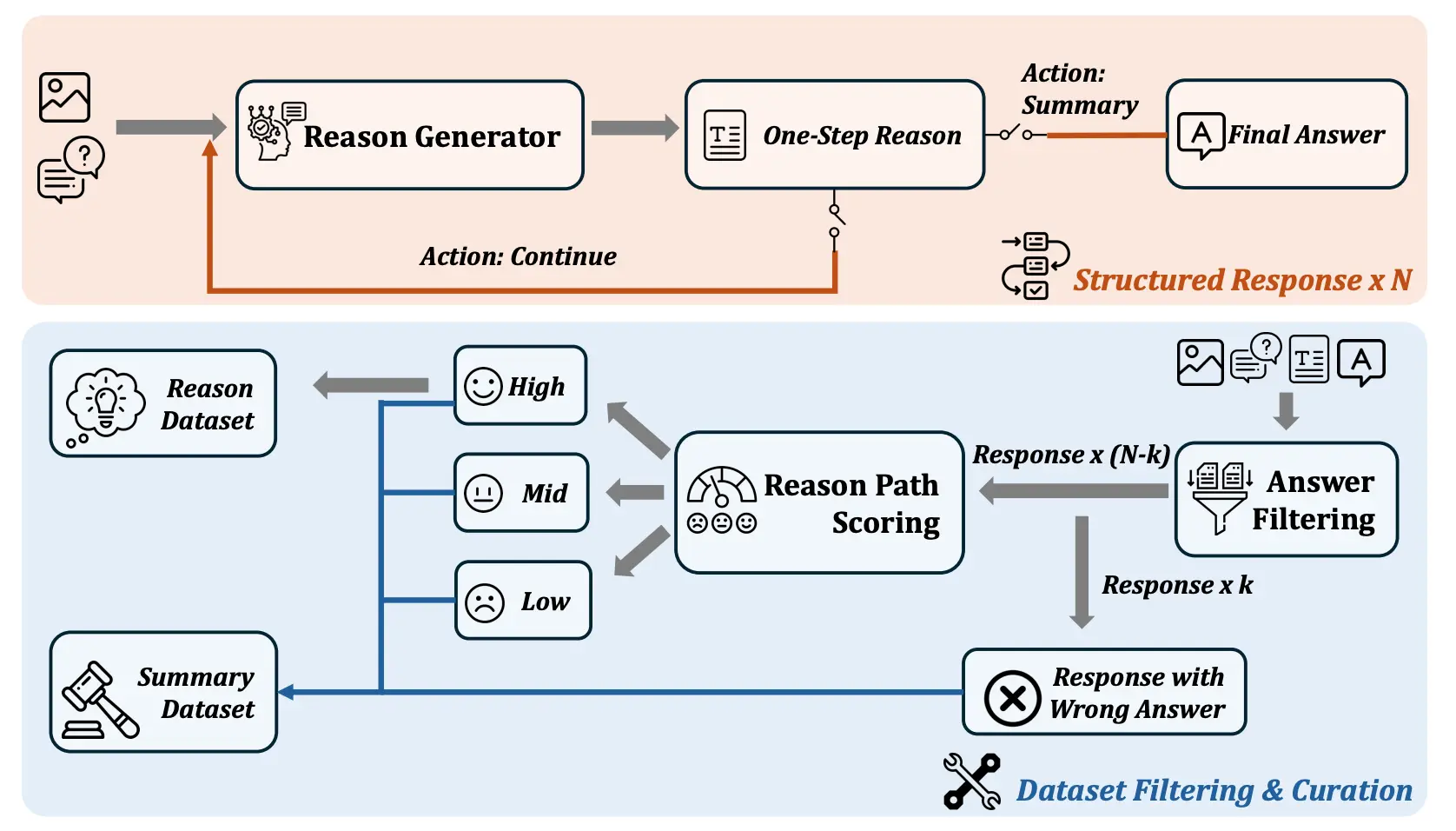
- 生成长而稳健的多模态推理数据:研究团队开发了一套自动化流程,能够在无需人工干预的情况下生成复杂多模态任务所需的长且结构化的推理数据。这一流程包括两个主要步骤:
- 使用渐进策略生成多样化的长推理路径。
- 应用多粒度评估机制保证生成数据的质量。
- 优化训练管道:为了充分利用上述生成的数据,研究人员还设计了一个高效的训练框架,特别针对增强多模态大型语言模型(MLLMs)的推理能力进行了优化。
解决挑战
在实验过程中,研究团队发现,直接使用长而复杂的推理数据来训练MLLMs并不能达到预期的效果。为此,他们创造性地引入了多代理系统的概念,该系统包含两个核心组件:
- 推理代理:负责执行复杂的长链推理任务。
- 总结代理:训练用于评估并总结推理代理的输出,确保推理结果的准确性和合理性。
此外,团队还开发了一种迭代DPO(Direct Preference Optimization)算法,以进一步提升推理代理的生成能力和稳定性。
主要功能和特点:
- 数据生成管道:Insight-V设计了一个两步流程来自动生成长且结构化的推理数据,无需人工劳动。这包括一个逐步生成多样化推理路径的策略和一个多粒度评估方法以确保数据质量。
- 多代理系统:Insight-V包含两个代理,一个推理代理(reasoning agent)负责执行长链推理,一个摘要代理(summary agent)负责判断和总结推理结果。
- 迭代DPO算法:通过迭代的直接偏好优化(DPO)算法来增强推理代理的生成稳定性和质量。
- 性能提升:在多种视觉推理基准测试中,Insight-V显示出显著的性能提升,尤其是在需要视觉推理的挑战性任务上。
工作原理:
Insight-V的工作原理基于以下三个核心组件:
- 结构化推理数据构建:通过逐步生成和多粒度评估来创建高质量、长链的推理数据。
- 多代理框架:通过训练一个推理代理来生成详细的推理过程,然后由摘要代理基于这些推理过程来回答问题。
- 两阶段训练管道:首先使用监督式微调来训练代理完成指定角色,然后通过直接偏好优化来进一步优化模型,使其更符合人类推理过程。
实验验证
基于改进后的LLaVA-NeXT模型和更为强大的基础MLLM,研究团队在多个需要视觉推理的多模态基准测试中验证了InsightV的有效性。结果显示,InsightV不仅在这些具有挑战性的任务中实现了显著的性能提升,而且在其他感知驱动的多模态任务中也能保持甚至提升原有的表现水平。