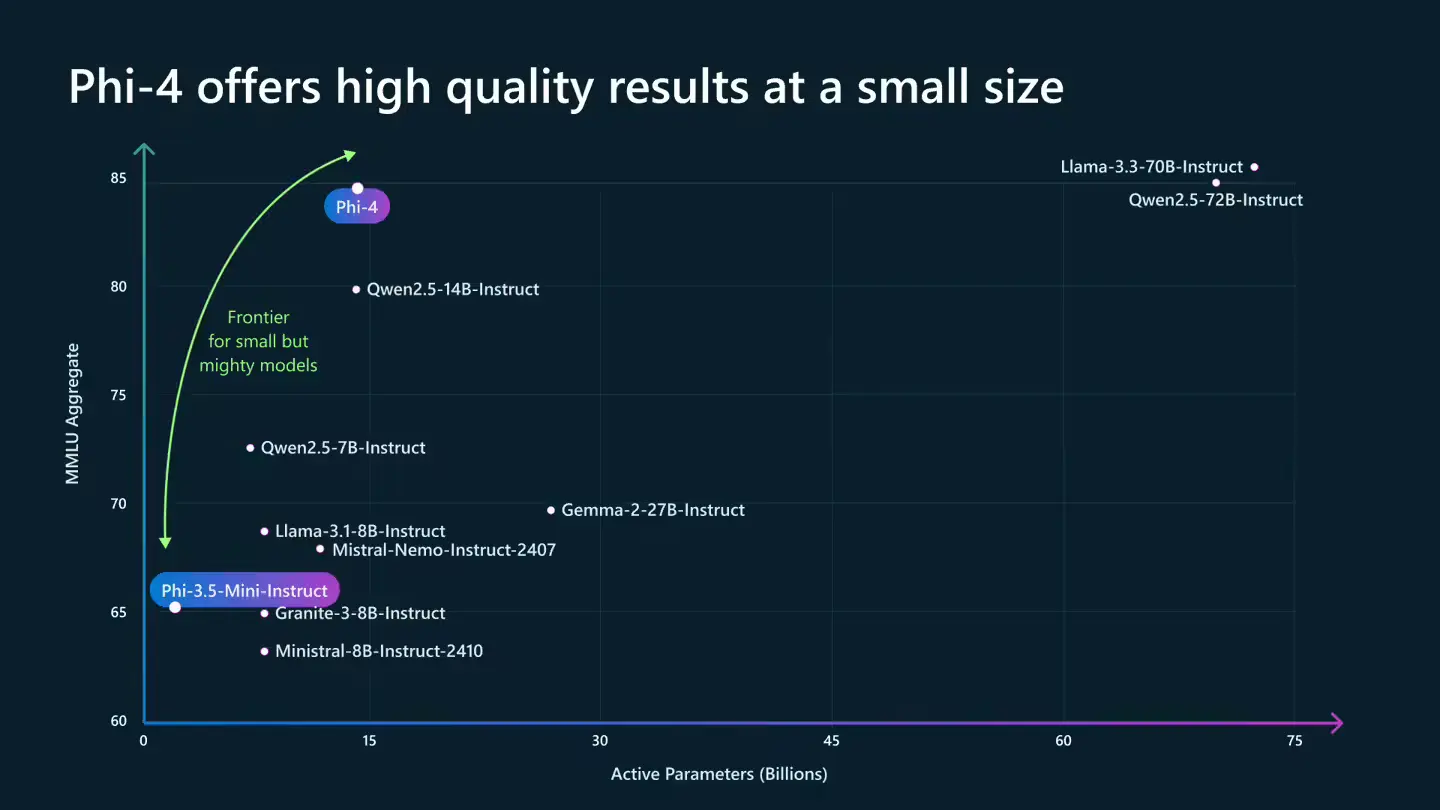
微软今天宣布推出 14B 参数“最先进”小型语言模型(SLM)Phi-4,除了传统的语言处理外,它还擅长数学等领域的复杂推理。Phi-4 是 Phi 系列小型语言模型的最新成员,官方表示其展示了微软继续探索 SLM 边界的可能性。
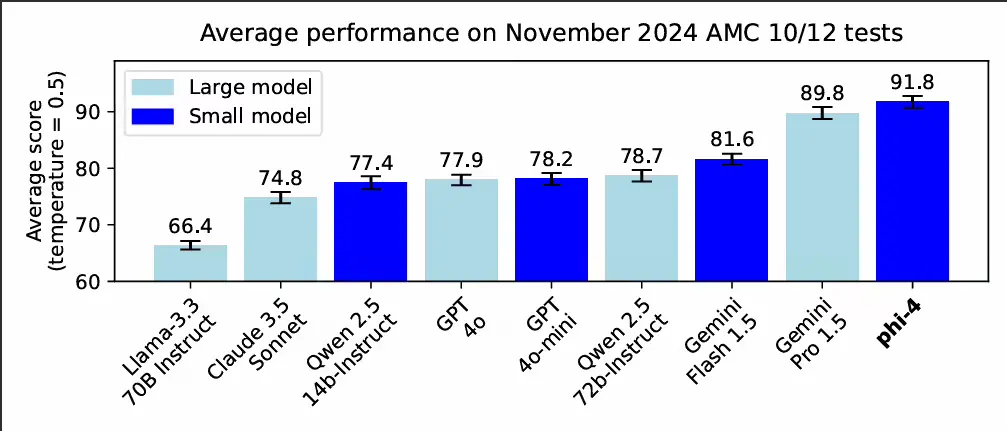
官方表示,得益于多方面的技术进步,包括采用高质量的合成数据集、精心挑选的高质量有机数据,以及训练后的创新,Phi-4 在数学推理方面超越了同类和更大规模的模型。其在数学竞赛问题上的表现超过了包括 Gemini Pro 1.5 在内的多个更大规模模型。
phi-4在训练过程中特别强调数据质量,并战略性地融入了合成数据。phi-4在STEM(科学、技术、工程和数学)领域的问答能力上超越了其教师模型(特别是GPT-4),显示出其数据生成和后训练技术的有效性。微软宣布,将“强大且负责任”的 AI 能力提供给所有使用 Phi 系列模型(包括 Phi-3.5-mini)的客户。
主要功能
- 合成数据预训练和中期训练:生成高质量的合成数据集,重点在于推理和问题解决能力。
- 高质量有机数据的策划和过滤:精选和过滤包括网络内容、授权书籍和代码库在内的有机数据源,以提取用于合成数据管道的种子,鼓励深度推理和优先教育价值。
- 后训练:通过创建新的SFT(监督式微调)数据集和开发基于关键令牌搜索的DPO(直接偏好优化)新技术,进一步优化模型输出。
主要特点
- 合成数据的大量使用:与大多数依赖有机数据源(如网络内容或代码)的模型不同,phi-4在训练中大量使用合成数据。
- 推理聚焦:通过多样化的技术生成的合成数据,增强了模型在复杂推理和问题解决方面的能力。
- 后训练创新:采用拒绝采样和DPO等技术来优化模型输出,特别是在关键令牌搜索方面的新技术。
工作原理
phi-4的工作原理涉及以下几个关键步骤:
- 数据生成:使用多种技术(如多代理提示、自我修订工作流和指令反转)生成合成数据。
- 模型训练:基于合成数据和精选的有机数据训练模型,使用特定的训练课程和数据混合。
- 后训练优化:通过SFT数据集和DPO对模型进行微调,以及使用关键令牌搜索技术来生成DPO对。