文章目录[隐藏]
视觉-语言模型(VLMs)使机器能够通过自然语言理解和推理视觉世界,广泛应用于图像字幕生成、视觉问题回答和多模态推理等领域。然而,大多数现有的VLMs主要设计和训练用于资源丰富的语言(如英语),这给资源匮乏语言的使用者留下了可访问性和可用性的巨大差距。这一差距凸显了开发能够满足全球受众需求的同时,在多样化的语言和文化背景下保持高性能的多语言系统的重要性。
在开发多语言VLMs时,一个关键的挑战是多语言数据集的可用性和质量。现有预训练数据集(如COCO、Visual Genome和LAION)主要关注英语,限制了它们在语言和文化上的泛化能力。此外,许多数据集包含有毒或偏见的内容,这会加剧刻板印象,并损害AI系统的道德部署。多样化的语言的有限代表性,加上存在文化不敏感的材料,阻碍了VLMs在代表性不足地区的性能,并引发了关于公平性和包容性的担忧。
Maya:应对数据质量和毒性的多语言VLM
为了解决这些局限性,来自Cisco Meraki、Cohere For AI Community、印第安纳大学布卢明顿分校、帝国理工学院、佐治亚理工学院、艾伦图灵研究所、孟加拉国工程技术大学、宾夕法尼亚大学、印度理工学院孟买分校、达姆施塔特工业大学、Articul8 AI、Capital One、印度理工学院丹巴德分校和MBZUAI的研究团队推出了Maya,这是一个拥有80亿参数的开源多语言多模态视觉-语言模型。Maya旨在克服现有数据集质量和毒性的局限性,提供一个更加公平、包容且高效的多语言VLM。
关键创新与技术细节
1. 高质量、多语言预训练数据集
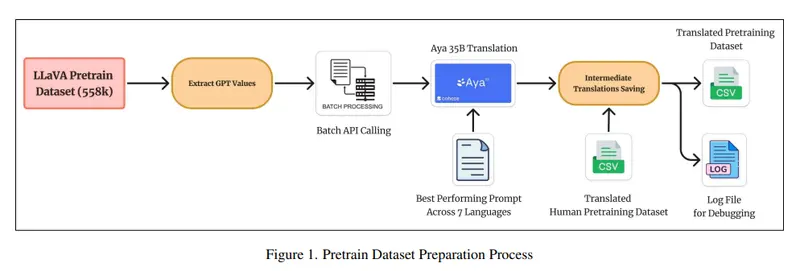
Maya的开发基于一个全新的预训练数据集,该数据集包含558,000个图像-文本对,平均分布在八种语言:英语、中文、法语、西班牙语、俄语、印地语、日语和阿拉伯语。这个数据集经过了严格的毒性过滤,使用了LLaVAGuard和Toxic-BERT等工具移除了超过7,531个有毒图像和字幕,确保了更干净的数据。此外,数据集的规模扩展到了440万个样本,覆盖了更多的语言和文化背景,从而提高了模型的泛化能力和公平性。
2. 平衡的数据分布与文化包容性
为了防止偏见并确保文化的包容性,Maya的开发团队特别注重平衡数据分布。通过对不同语言和文化背景的数据进行精心采样和处理,Maya能够在多种语言上保持一致的性能表现,避免了某些语言或文化的过度代表或忽视。这种平衡的数据分布不仅提高了模型的泛化能力,还促进了公平性和多样性。
3. 先进的架构设计
Maya的架构建立在LLaVA框架之上,并融入了多种先进技术,以优化图像-文本对齐和多语言适应:
- SigLIP:Maya采用了SigLIP作为视觉编码器,这是一种能够处理可变输入维度的高效视觉编码器,适用于不同分辨率的图像。SigLIP通过学习图像特征的空间结构,增强了模型的视觉理解能力。
- Aya-23:Maya的语言模型部分基于Aya-23,这是一个在23种语言上训练的多语言模型。Aya-23通过共享跨语言的表示,增强了模型的多语言理解和生成能力,使得Maya能够在多种语言之间进行无缝切换。
- 两层投影矩阵:为了将图像特征桥接到语言特征,Maya引入了一个两层投影矩阵,优化了图像和文本之间的对齐,同时保持了计算效率。这种设计使得模型能够在处理复杂的多模态任务时表现出色。
4. 高效的训练过程
Maya的预训练在8xH100 GPUs上进行,全局批量大小为256,预训练大约需要20小时。指令微调使用了PALO 150K数据集,微调过程大约需要48小时。这种高效的训练策略确保了模型能够在较短的时间内达到高质量的输出,同时保持了良好的性能。
性能评估与亮点
Maya在多个多语言基准测试中表现出色,特别是在LLaVA-Bench-In-The-Wild上,Maya在八种语言中的五种语言上超过了类似大小的模型(如LLaVA-7B和PALO-7B),尤其是在阿拉伯语方面取得了显著的成就。这归功于其强大的翻译和数据集设计,使得Maya能够在资源匮乏的语言中也表现出色。
在仅限英语的基准测试中,Maya保持了竞争性的准确性,在文本翻译和数值计算等任务中,无毒性变体观察到了边际增益。然而,一些复杂的推理任务显示出了轻微的性能下降,表明移除多样化、可能有毒的内容可能会影响某些能力。尽管如此,Maya的成功仍然证明了在保持道德和公平的前提下,多语言VLM可以实现高性能。
关键要点与亮点总结
- 高质量、多语言预训练数据集:Maya的预训练数据集包括558,000个图像-文本对,扩展到八种语言中的440万个样本。严格的毒性过滤移除了7,531个有毒元素,确保了更干净的数据。
- 平衡的数据分布与文化包容性:Maya支持八种语言,通过优化的翻译和预训练策略实现了平衡的数据分布和文化包容性。
- 先进的架构设计:Maya采用了SigLIP用于视觉编码和Aya-23用于多语言语言建模,使得高质量的图像-文本对齐和跨语言理解成为可能。
- 出色的多语言性能:Maya在五种语言上超过了类似大小的模型,并在几个基准测试中与更大的模型相匹配。
- 道德与公平的AI实践:Maya通过解决毒性和偏见问题,为道德和公平的AI实践树立了先例。
通过推出Maya,研究人员解决了VLMs中有限的多语言和文化敏感数据集问题。这个模型结合了一个创新的数据集,包含558,000个跨八种语言的图像-文本对,以及严格的毒性过滤和平衡的代表性,以确保包容性和道德部署。利用先进的架构和多语言适应技术,Maya在多种语言上超过了类似大小的模型,为多语言AI的发展树立了新的标杆。Maya的成功不仅推动了多模态AI的进步,还为全球范围内的公平和包容性AI应用提供了重要的范例。