文章目录[隐藏]
阿里巴巴通义实验室近期推出了一款名为MinMo的多模态语音大模型,该模型拥有约80亿参数,专注于提升语音理解和生成能力。MinMo旨在克服当前语音交互系统面临的挑战,包括处理语音内容、情感语调及音频线索,同时提供准确且连贯的响应。
解决现有问题
当前的语音交互系统主要分为两类:原生多模态模型和对齐多模态模型。前者虽然集成了语音和文本的理解与生成,但由于语音序列较长导致效率低下,并且面临语音数据有限的问题;后者则试图将语音能力与预训练的文本模型结合,但往往缺乏对复杂语音任务的支持,如情感识别或说话人分析。此外,这些模型尚未充分评估其在不同说话风格或全双工会话中的表现。
MinMo的技术创新
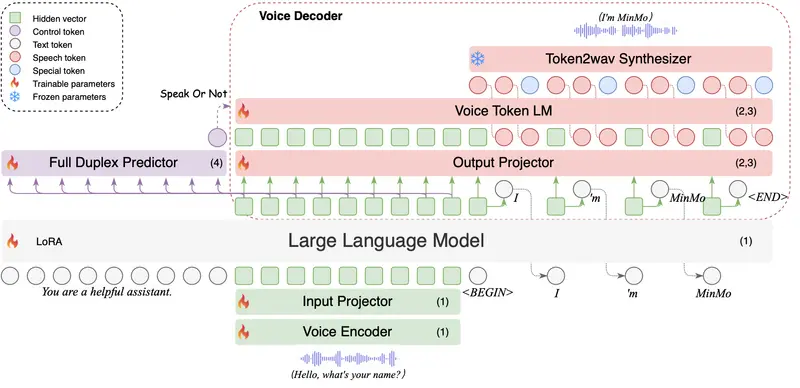
为了解决这些问题,MinMo采用了多阶段训练方法来对齐语音和文本模态,支持多种任务,如语音转文本、文本转语音、语音转语音以及双工交互。其核心组件包括:
- SenseVoice-large:用于多语言语音和情感识别的语音编码器。
- Qwen2.5-7B-instruct:用于文本处理的大规模语言模型(LLM)。
- CosyVoice 2:用于高效音频生成的模块。
- AR流式Transformer语音解码器:提升性能并减少延迟。
MinMo在超过140万小时的语音数据上进行了训练,这使得它不仅能够在多个基准测试中达到最先进的性能,还能有效防止对文本LLM能力的灾难性遗忘。
性能表现
研究人员对MinMo进行了广泛的评估,结果显示:
- 在多语言语音识别任务中,MinMo的表现优于Whisper Large v3等模型,特别是在多语言语音翻译方面达到了最新的技术高度。
- 在语音转文本增强、语音情感识别(SER)和音频事件理解等方面,MinMo同样表现出色。
- 使用Fleur数据集进行的语言识别任务中,MinMo实现了85.3%的准确率,超越了所有先前的模型。
- 在性别检测、年龄估计和标点插入等任务中,MinMo也展现了强劲的表现。
- 在语音生成任务中,特别是在方言和角色扮演任务中,MinMo的准确率达到98.4%,远超GLM-4-Voice的63.1%。
尽管MinMo在语音转语音任务中的表现有所下降,但它在对话任务和逻辑推理中仍表现出高灵敏度,轮换预测性能约为99%,并且能够实现约600毫秒的全双工交互响应延迟。