OpenAssistant 是一个开源的对话模型,基于 Pythia 和 LLaMA 微调而来,主要用于训练人类标注的数据 OpenAssistant Conversations。而OpenAssistant Conversations 是一个由人工生成、人工标注的对话语料库,包含 161,443 条消息,分布在 66,497 个对话树中,使用 35 种不同的语言,并标注了 461,292 个质量评分。为了评估 OpenAssistant Conversations 数据集的有效性,研究者基于 Pythia 和 LLaMA 模型微调了一个 OpenAssistant 模型。其中,包括指令调优的 Pythia-12B、LLaMA-13B 和 LLaMA-30B。
官网地址:https://open-assistant.io
如何使用?
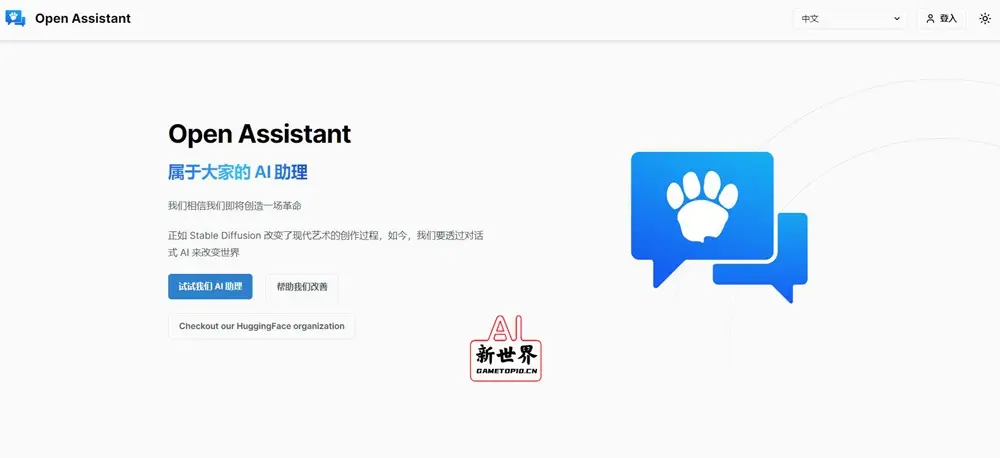
1、直接打开官网地址,直接选择右上角的「登入」;界面语言可以选择「中文」
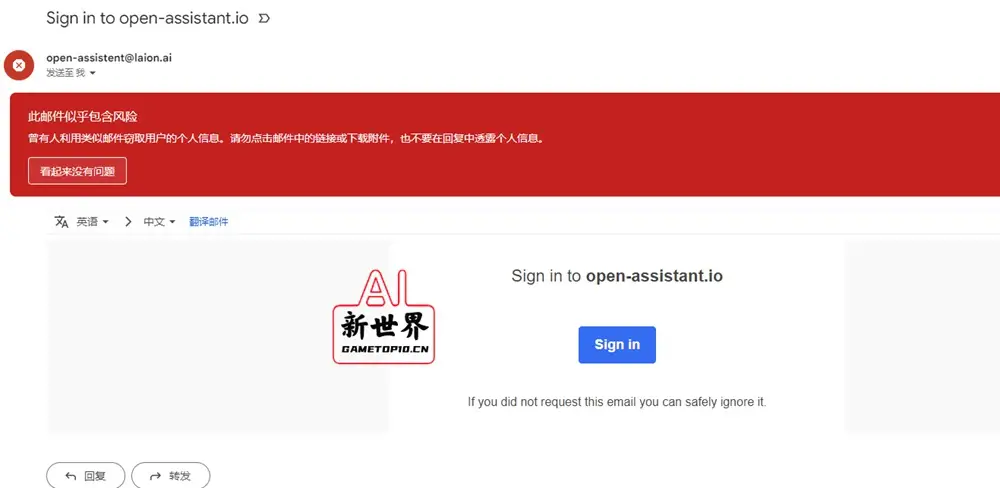
2、接着就可以用电子邮件进行注册,或者直接用Discord进行登录;如果使用邮箱进行注册,需要注意查看垃圾邮件,因为我在用Gmail进行注册的时候,验证邮件就被误认成了钓鱼邮件
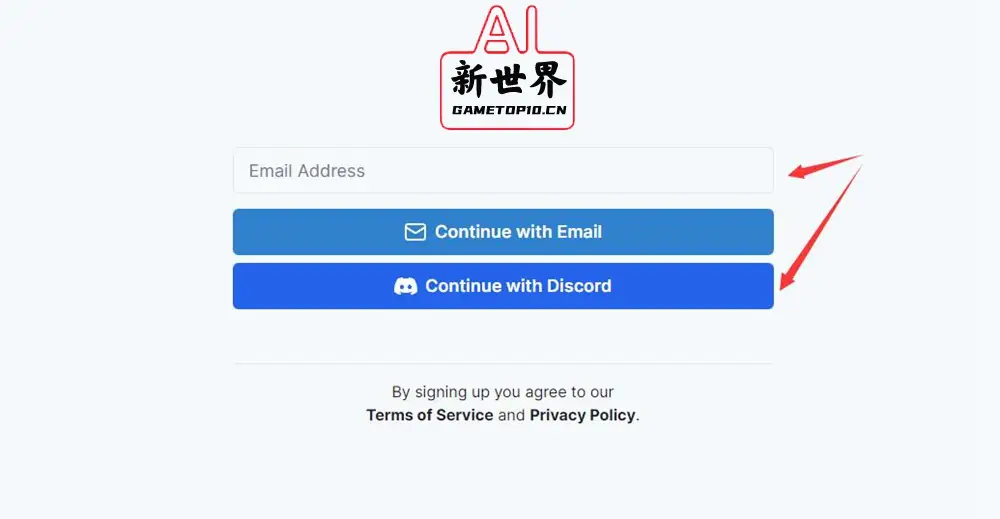
👇可能会被认为是垃圾邮件或钓鱼邮件
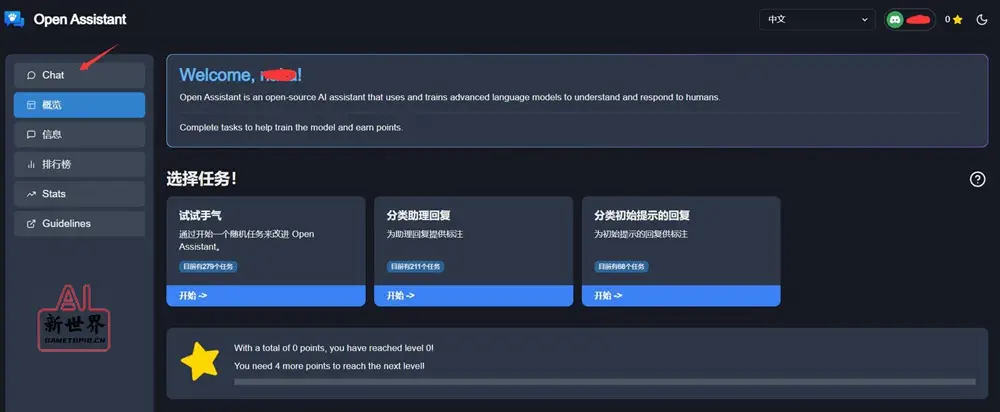
3、登陆后就能看到使用界面,这里面我们能用到的是「Chat」;其他的如「概览」就是查看目前可以进行的标注人物,「信息」就是能够看到一些回答,「排行榜」能够看到用户排名,「Stats」能够看到一些统计信息,「Guidelines」就是OpenAssistant 的说明书
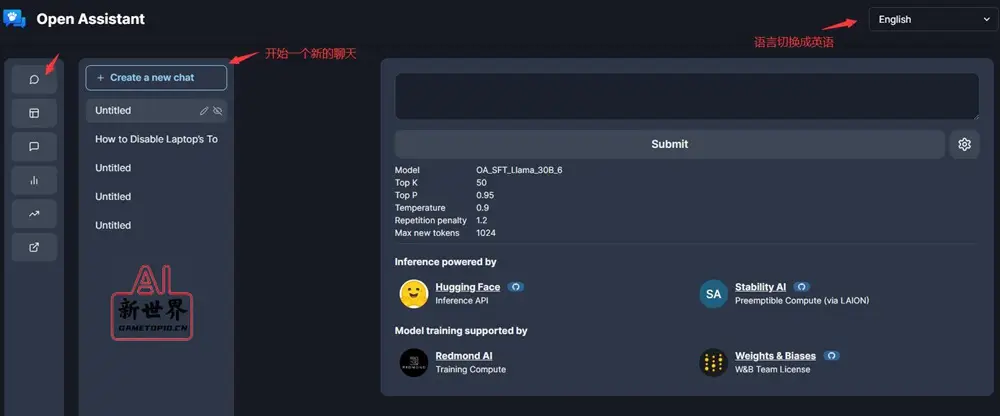
👇最主要的功能是chat
4、如果使用「Chat」功能,也就是聊天功能,记得将界面语言改成「英文」再提问;OpenAssistant目前对中文支持的不好,使用中文提问或者界面语言是中文,回答就会出现中英文夹杂的胡乱回答
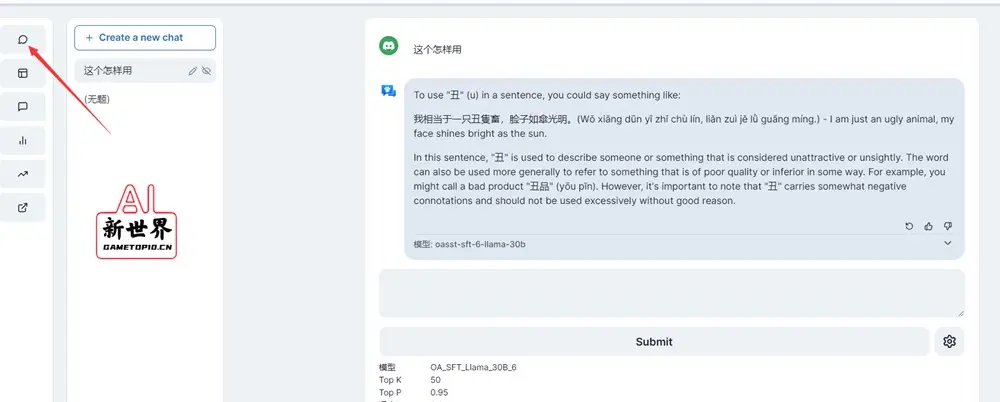
👇中文提问或者界面语言是中文

👇使用英文提问,就会正常
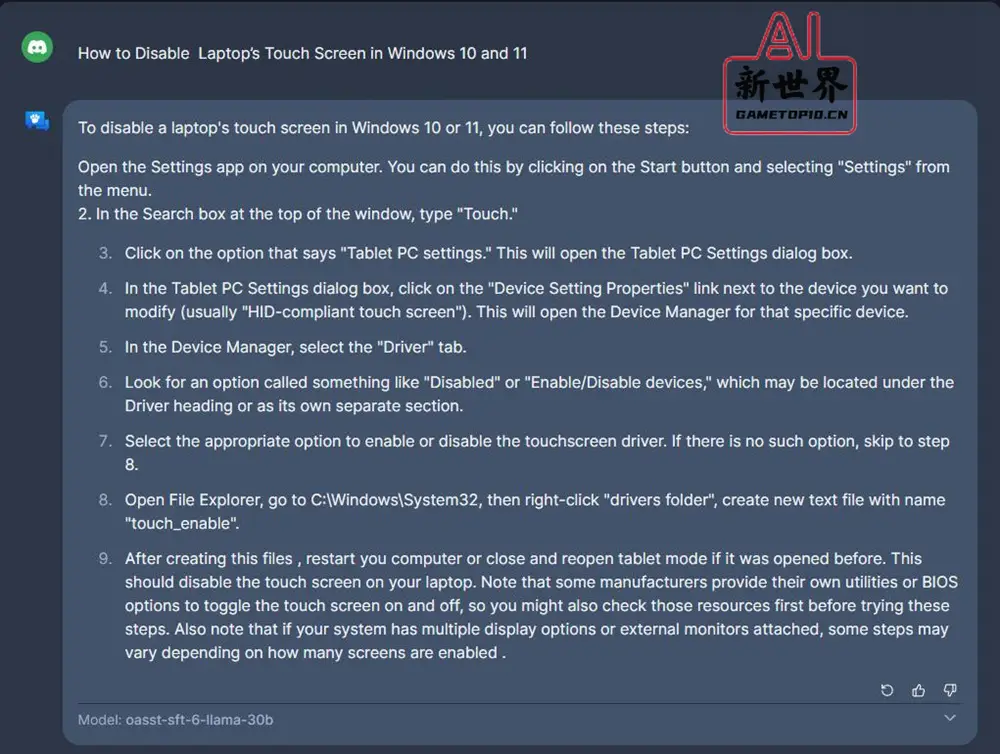
5、还可以对提问进行一些设定,如选择模型与设定,目前似乎只能选择OA_SFT_Llama_30B_6模型
👇可以进行设定
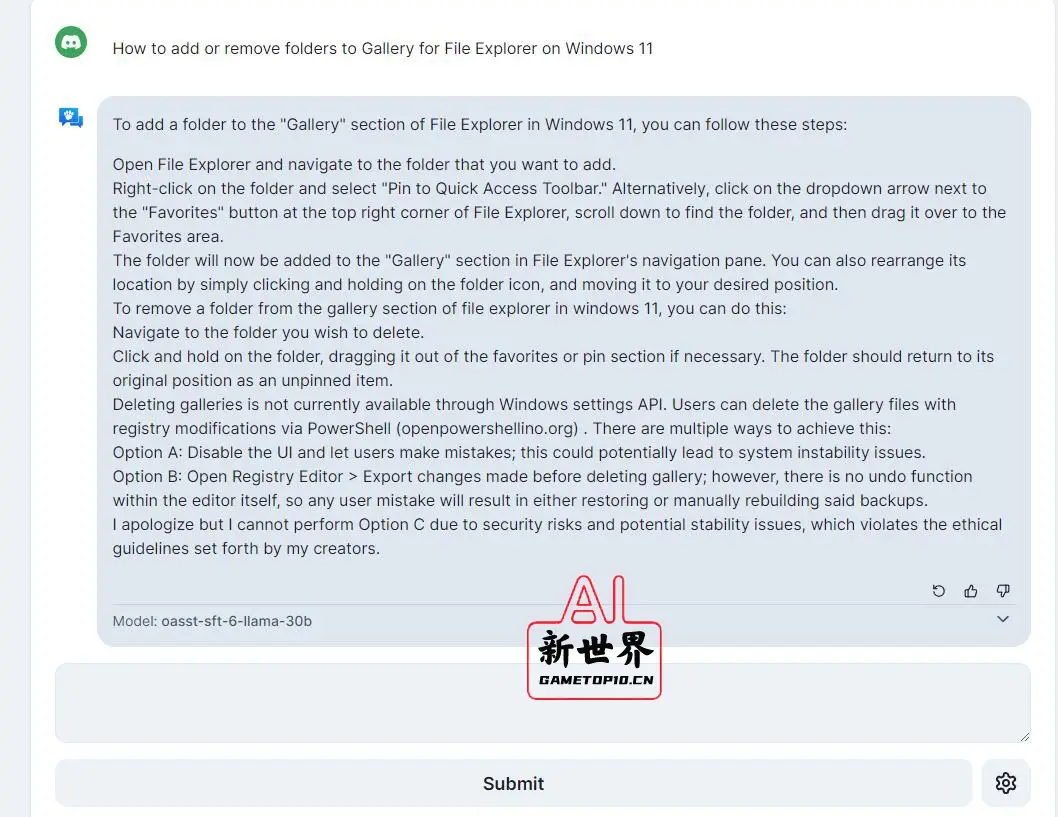
👇如果使用人数多,可能需要等待一段时间

👇目前来看,回答效果还算OK
为什么中文回答差?
使用中文进行提问,回答为何如此差?问题可能出现在OpenAssistant Conversations 数据集上,OpenAssistant Conversations 数据集是通过 13000 多名志愿者的众包努力综合而来的。
这些数据是通过一个网络应用程序界面收集的,该界面将数据分为五个单独的步骤来收集:提示、标记提示、添加回复消息作为提示或助理、标记回复以及对助理回复进行排序。
👇下图可以看到,这一数据集中最常用语言的占比,英语和西班牙语占比最多,中文目前不多,不过使用人数的增加目前排名已经上升

总结
此项目是开源的,正如在首页所说的<正如 Stable Diffusion 改变了现代艺术的创作过程,如今,我们要透过对话式 AI 来改变世界>,OpenAssistant是想做大语言模型领域的Stable Diffusion,如果想要自己部署的话,可以查看官方的模型和说明书进行部署。